
Embedding extraction
Reckoning with AI


My aim in this series is to think through the likely trajectory of current AI-technologies, and what some of the potential ramifications might be (notes one and two). In doing so, I’m not attempting to assess how powerful these current models are or could become, but assuming that they have reached a stage of development consequential enough to be impactful. On this, my thinking echoes Gary Marcus:
I am not worried, immediately, about “AGI risk” (the risk of superintelligent machines beyond our control), in the near term I am worried about what I will call “MAI risk”—Mediocre AI that is unreliable (a la Bing and GPT-4) but widely deployed—both in terms of the sheer number of people using it, and in terms of the access that the software has to the world.
Elsewhere Marcus captures the constellation of forces that makes the current context potentially so problematic:
We have a perfect storm of corporate irresponsibility, widespread adoption, lack of regulation and a huge number of unknowns.
As I considered in a previous note, these conditions have been powerfully captured by Shoshana Zuboff’s work:
The institutional order of surveillance capitalism is an information oligopoly upon which democratic and illiberal governments alike depend for population-scale extraction of human-generated data, computation and prediction.
Here it is the term ‘extraction’ that I want to focus on, and its centrality to the way these AI-technologies are structured. The central claim is that a likely consequence of the current trajectory of AI development is the further embedding of extraction as an ordering principle for economy and society. And this is ultimately not a good thing for most of us or the world.
There are some rather straightforward ways that an extractivist mindset is present. ChatGPT is trained using a technique called reinforcement learning from human feedback (RLHF). This involves people checking ChatGPT prompts and responses to identify results that might be considered dangerous, harmful or very problematic. At least some of this work was outsourced to Kenyan contractors earning less than $2 per hour. This can be contrasted with OpenAI projecting revenue of $1 billion by 2024.
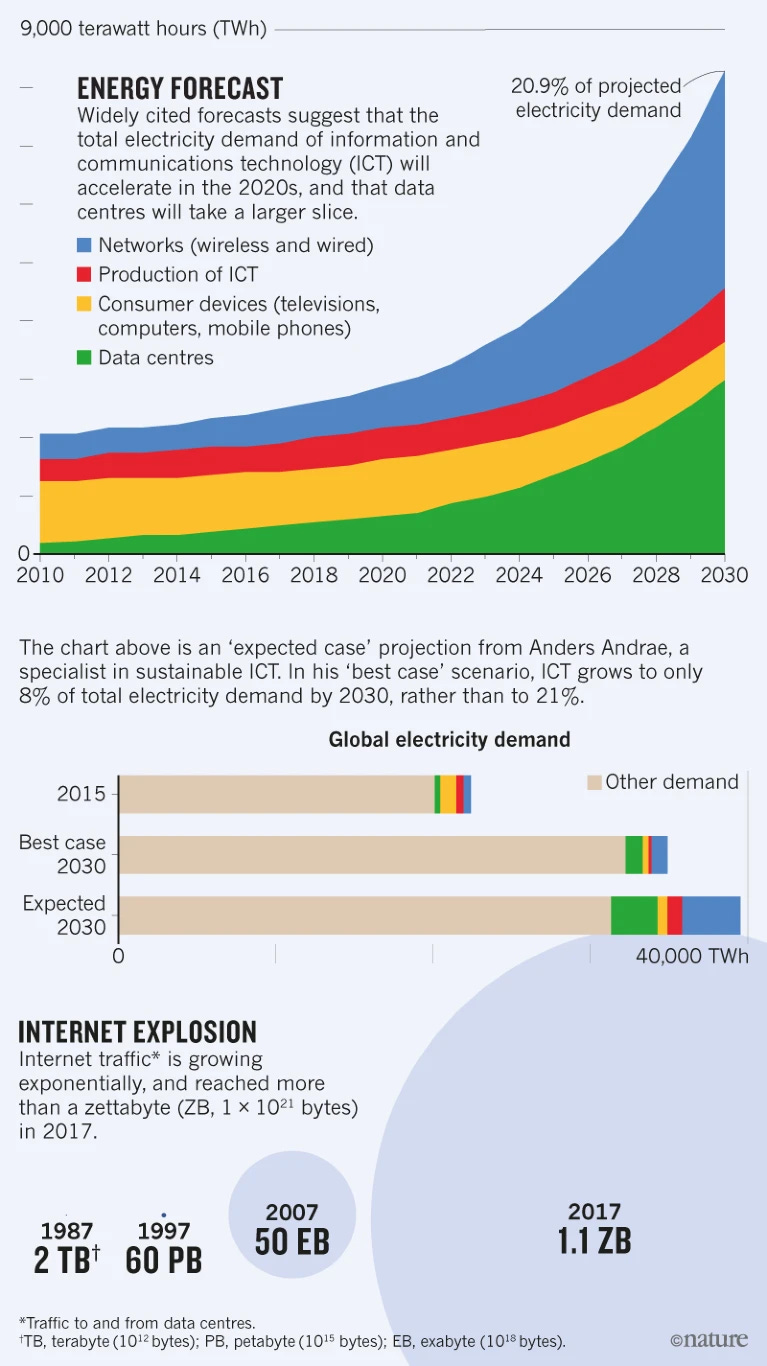
It is also important to recognise that these technologies use considerable amounts of energy, and with that, have a sizeable environmental impact. The exact carbon footprint of ChatGPT and other models is unclear, although calculations suggest it is large, and will continue to grow. Certainly there are ways of making the models more energy efficient, but this does not appear to be a priority. In 2018, it was reported in Nature that carbon emissions from the information and communications technology ecosystem are more than 2% of global emissions. Given the rapidly rising demand for AI-technologies, it can be expected that this will lead to increasing energy demands from the sector.
Underlying this, there are minerals and raw resources needed for computers and all the other electronic devices we use. This is extraction in its most immediate sense, with one of the most acute cases being artisanal mining of cobalt in the Democratic Republic of the Congo. In Siddharth Kara’s recently published book on the topic, Cobalt Red, he details the terrible conditions of miners there:
Child labor, subhuman working conditions, toxic and potentially radioactive exposure, wages that rarely exceeded two dollars per day, and an untold rash of injuries were the norm. Astonishingly, the appalling conditions at the mines remained almost entirely invisible to the outside world.
This is not meant to be a ‘gotcha’ point, the way AI companies rely on energy and natural resources that are often tied to exploitative structures is not distinctive or unique, far from it. It is worth foregrounding precisely because we tend to think about it so little. In ‘Anatomy of an AI System’, Kate Crawford and Vladan Joler use the example of Amazon Echo to identify how everyday products are ‘interlaced chains of resource extraction, human labor and algorithmic processing across networks of mining, logistics, distribution, prediction and optimization.’ They observe:
Put simply: each small moment of convenience – be it answering a question, turning on a light, or playing a song – requires a vast planetary network, fueled by the extraction of non-renewable materials, labor, and data. The scale of resources required is many magnitudes greater than the energy and labor it would take a human to operate a household appliance or flick a switch. A full accounting for these costs is almost impossible, but it is increasingly important that we grasp the scale and scope if we are to understand and govern the technical infrastructures that thread through our lives.
The Amazon Echo example is an apt one, as the device has effectively been optimised for surveillance capitalism, capturing and extracting considerable amounts of user data for targeted advertising. This returns us to the logic of extraction. As Ye et al. outline in their article, ‘The incursions of extractivism: moving from dispersed places to global capitalism’:
Today power is grounded in control over flows – and through this control material resources are also controlled.
They further propose:
The essence of extractivism is not located in the type of resources involved. It resides, instead, in control, and in resource-mining. Extractive capture is characterized by monopolistic control over a wide range of resources that is exerted by, and through, an operational centre. Through their control over resource-combination and resource-use, extractivist systems are able to generate a huge value flow towards the operational centre. The value that comes with resource-use is shifted towards the centre: it is appropriated. This value shift is structured as resource-mining; the resources used are not developed by the operational centre: they are taken over, mined, and after exhaustion, they are replaced by resources located elsewhere. The resources are not reproduced: they are literally mined.
How does apply to thinking about AI? Here it is worth considering the training data on which these large language models have been trained. We know that these have used huge swathes of information from the internet, a mixture of publicly available and copyrighted material. It appears likely that this includes pirated ebooks, and in the case of Google’s Bard, it has been suggested about a quarter of the data comes from CommonCrawl and Wikipedia, with the remaining three quarters coming ‘from vaguely-identified sources’. It is also worth noting that OpenAI has moved towards sharing less information about its model, including how it has been trained, because of concerns around competition and safety. Regardless, we do know that these models are being built from a massive storehouse of human knowledge and creativity available online, created by the many, with the power and resources accruing going to the few. These dynamics are extractive in nature and function.
Returning to Ye et al.:
Extractivist activities are built on resources that have been provided by nature and/or previous generations – resources that are, as it were, ‘awaiting’ exploitation and which, through such exploitation, are depleted (instead of being reproduced).
The training data for AI is a resource provided by previous generations, compiled and stored online. It might be questioned whether this frame of extractivism is fully applicable to AI. Taken to its logical extreme, however, it might fit. A world in which more and more content on the internet becomes produced by AI, and the less that people themselves actively engage in activities necessary to create texts (broadly understood), over time might actually work towards undermining the reproduction of human creativity and culture. Even if this is stretching the point, it is worth considering about the consequences of reducing the sum total of human learning to a resource to be mined and exploited.
Wendy Liu captures this dynamic of the common being appropriated by the private:
If the outputs of large language models such as GPT-4 feel intelligent and familiar to us, it’s because they are derived from the same content that we ourselves have used to make sense of the world, and perhaps even helped create. Genuine technical achievements went into the development of GPT-4, but the resulting technology would be functionally useless without the input of a data set that represents a slice of the combined insight, creativity, and well, stupidity of humanity. In that way, modern AI research resembles a digital “enclosure of the commons,” whereby the informational heritage of humanity—a collective treasure that cannot really be owned by anyone—is seen by corporations primarily as a source of potential profit.
A ‘digital enclosure of the commons’ offers a powerful way to consider such matters, especially given the way these companies are effectively raiding the internet for people’s work, apparently with little concern for copyright or compensation, and repurposing it through these AI systems. Anja Nygren, Markus Kröger & Barry Gills observe that, ‘striking relationships exist between accelerated extractivism and grinding inequality in the midst of abundance and accumulation’, and it appears that similar dynamics are at play in the present development of AI.
As a way of finishing, a text that helped me think through how deeply the logic of extraction has become embedded into our way of living is Wendell Berry’s 1971 essay, ‘Think Little’. In considering a number of separate social movements related to civil rights, peace, and the environment, Berry suggested that the division is artificial: ‘war and oppression and pollution are not separate issues, but are aspects of the same issue’ and that, ‘we would be fools to believe that we could solve any one of these problems without solving the others.’ The reason is that the underlying cause is the same: ‘the mentality of greed and exploitation.’ What Berry captured is a lack of care with the conditions that provide for and sustain us, and the consequences that flow from this arrogant inattentiveness.
Practices of extraction are central to mounting environmental and societal problems. The AI models now being rolled out replicate and reinforce this unsustainable approach to our world. At a time when we desperately need to find more sustainable ways of living together, it is difficult to see how further embedding extractive systems into our modes of living is going to help. As Berry put it:
our great dangerousness is that, locked in our selfish and myopic economy, we have been willing to change or destroy far beyond our power to understand.